Einführung in GraphQL im Backend
GraphQL gewinnt immer mehr an Beliebtheit. Umso wichtiger ist es, dass Entwickler einen Überblick über die Prinzipien und die Funktionsweise dieses neuen Ansatzes für APIs haben. In diesem Artikel möchte ich auf diese ersten Schritte eingehen: GraphQL als statisch typisierte Sprache zum Abfragen und Aktualisieren von Daten. Wie kannst Du eine GraphQL-Schnittstelle bereitstellen und welche Vorteile kannst Du daraus ziehen?
Achtung: Dieser Artikel ist Teil 1 der Reihe "Wie man erfolgreich sein eigenes GraphQL-Backend implementiert". Teil 2 wird bald™ erscheinen und Lösungen für das leidige N+1-Problem behandeln, das die Performance unserer Anwendungen beeinträchtigen kann.
Was ist GraphQL?
ZLNG: GraphQL ist eine statisch typisierte Sprache, die es einem Client erlaubt, Daten von einer Art Server abzufragen.
Das hat wahrscheinlich nicht wirklich geholfen, oder? Warum lernen wir nicht an einem Beispiel. (Vollständiger Quellcode hier)
Zuerst müssen wir das Schema definieren. Dieses definiert Datentypen und Schnittstellen, die unsere API zur Verfügung stellt:
# ./src/schema.graphql
type User {
id: Int!
name: String!
friends: [User!]!
}
type Query {
user(id: Int!): User
}
type Mutation {
setUserName(id: Int!, name: String!): User
}
Wir haben diesen Query-Typ, der den Ausgangspunkt für die Abfrage von Daten unserer API beschreibt. Wir können sehen, dass wir eine mögliche Abfrage anbieten: user. Dort müssen wir einen Integer an das id-Feld übergeben und erhalten im Gegenzug ein User-Objekt. Auf diesem Objekt können wir die Felder id, name und friends abfragen, wobei friends ein Array von user-Objekten zurückgibt.(Anmerkung: Die Ausrufezeichen hinter den Typen kennzeichnen Felder oder Argumente, die niemals fehlen dürfen).
Zusätzlich haben wir den Typ Mutation definiert. Dieser definiert alle Endpunkte, die Daten auf unserem Server updaten (=mutieren). Diese Mutations können auch willkürliche Werte zurückgeben. In unserem Fall gibt die setUserName-Mutation den aktualisierten user zurück.
query {
user(id: 1) {
id
name
}
}
mutation {
setUserName(id: 1, name: "new name") {
id
name
}
}
Hier sehen wir eine Beispiel Query und eine Beispiel Mutation. Es sieht ein bisschen wie JSON aus, nur ohne die Werte und mit Funktionen und Argumenten. Konzentrieren wir uns auf die Query: Wie du siehst, fragen wir die Felder id und name des Benutzers mit der ID 1 ab. Das Feld friends wird nicht abgefragt und wird daher auch nicht mit ausgeliefert. Die zurückgegebene JSON-Antwort würde wie folgt aussehen:
{
"data": {
"user": {
"id": 1,
"name": "Luke Skywalker"
}
}
}
GraphQL selbst schreibt nicht vor, wie diese Abfrage zwischen dem Client und dem GraphQL-Server transportiert wird, in der Praxis geschieht dies jedoch üblicherweise über einen HTTP-POST-Request mit einem JSON-Body, der wie folgt aussieht:
{
"query": "query {↵ user(id: 1) {↵ id↵ name↵ }↵}",
"variables": null
}
Das sollte soweit als Einführung in die Grundlagen der Sprache selbst ausreichen. Natürlich gibt es noch weitere Sprachfeatures wie Fragments oder Directives, aber die brauchen wir für diesen Beitrag nicht. Wenn du Interesse hast und mehr erfahren möchtest, schauen Dir am besten die offizielle Dokumentation an.
Setzen wir unseren eigenen GraphQL Server um
Der nächste Schritt beim Hinzufügen von GraphQL zu unserer Anwendung ist das Laden unseres definierten Schemas aus ./schema.graphql:
// ./src/schema.js
const fs = require("fs");
const path = require("path");
const graphql = require("graphql");
const schema = graphql.buildSchema(
fs.readFileSync(path.join(__dirname, "./schema.graphql")).toString()
);
module.exports = schema;
Anmerkung: Viele andere Sprachen verfolgen den Code-First-Ansatz: Das Schema wird nicht in der Schema-Definitionssprache definiert, sondern als Objekte oder Klassen direkt im Code. Dies ist auch in der JavaScript-Implementierung von GraphQL möglich.
Als nächstes müssen wir einen Endpunkt zu unserer Node-App hinzufügen, der auf Graphql-Anfragen hört:
// ./src/index.js
const express = require("express");
const graphqlHTTP = require("express-graphql");
const rootValue = require("./rootValue");
const schema = require("./schema");
// Instantiate express app
const app = express();
app.use(
"/graphql",
graphqlHTTP({
schema,
rootValue,
graphiql: true,
})
);
app.listen(4000, () =>
console.log("Listening on http://localhost:4000/graphql")
);
Dadurch wird ein Webserver auf Port 4000 gestartet. Immer wenn eine Anfrage unter http://localhost:4000/graphql eintrifft, leiten wir diesen Request an die graphqlHTTP-Bibliothek weiter.
Auf diese Weise integriert sich GraphQL sehr gut in Deine Standard-Request-Pipeline. Es gibt Bindings für die gängigsten Frameworks wie graphql-dotnet für .Net/C#, GraphQLBundle für Symfony/PHP oder GraphQL Java für Spring/Java.
Zurück zu unserem Beispiel: Wir haben der GraphQL-Engine 2 wichtige Werte zur Verfügung gestellt:
schema: Dieses wird verwendet, um alle eingehenden Anfragen zu validieren.rootValue: Wird benutzt, um die Daten "aufzulösen", die zurückgegeben werden sollen.
Nun stellen wir uns vor, wir senden unsere Beispielanfrage von vorhin an diesen Endpunkt. Das sind (mehr oder weniger) die Schritte, die die GraphQL Engine verfolgt:
- (Validiere die Anfrage)
- Lies das erste Top-Level-Feld in der Abfrage ein:
user - Prüfe, ob der
rootValueein Felduserhat,- Wenn es direkt ein Objekt oder ein anderer Wert ist, lege dieses Objekt für die Auflösung der untergeordneten Felder zur Seite.
- Wenn es eine Funktion ist, rufe sie mit den Argumenten aus dem
user-Feld der Anfrage auf und übergib dasexpress-Request-Objekt als zweites Argument.- Wenn die Funktion ein Promise zurückgibt, warte, bis es aufgelöst ist, und lege das Ergebnis zur Seite.
- Wenn die Funktion einen einfachen Wert zurückgibt, lege diesen zur Seite.
- Wir haben jetzt ein Ergebnis für das
user-Feld. Die Engine prüft nun die Felder auf der nächsten Ebene der Abfrage:idundnameund versucht, diese mit dem Ergebnis desuser-Feldes aufzulösen. - Die Bibliothek prüft also wieder, ob dieses Objekt ein Feld
idhat und löst dieses auf (Basiswerte übernehmen, Funktionen aufrufen, auf Promises warten). - Dasselbe wird mit dem
id-Feld gemacht. - Wiederhole diese Schritten rekursiv, bis alle Felder der Query im finalen Objektbaum vorhanden sind.
- Gib Sie dieses Objekt mit allen Feldern zurück, die der Client als JSON-Antwort angefordert hat.
Das ganze sollte klarer werden, wenn wir uns ansehen, wie der rootValue im Code aussehen könnte:
// ./src/rootValue.js
const rootValue = {
user: async (args, req) => {
return await req.dependencies.userRepository.getById(args.id);
},
};
module.exports = rootValue;
Hier haben wir eine Funktion auf dem Feld user definiert, die einen Benutzer aus dem userRepository abruft. Es spielt nicht wirklich eine Rolle, woher wir das userRepository bekommen, wir hätten es auch direkt aus einer anderen Datei importieren können. In unserem Fall haben wir es auf das express-Request-Objekt in einer früheren Middleware gelegt.
Und hier ist der Code für dieses Repository:
// ./src/user/UserRepository.js
// The userQueries contain code that accesses the database.
const userQueries = require("./user.queries");
class UserRepository {
async getById(id) {
const userRow = await userQueries.getById(id);
return { ...userRow, friends: () => this.getFriendsOfUser(id) };
}
async getFriendsOfUser(userId) {
const friendIds = await userQueries.getFriendIds(userId);
const friendUserRows = await userQueries.getByIds(friendIds);
return friendUserRows.map((friend) => ({
...friend,
friends: () => this.getFriendsOfUser(friend.id),
}));
}
}
module.exports = UserRepository;
Die Funktion userQueries.getById gibt die Zeile für den Benutzer aus der Datenbank zurück. Diese Zeile enthält nur die Felder id und name (sodass diese direkt von der Engine aufgelöst werden können, ohne eine Funktion aufrufen zu müssen). Da die GraphQL-Engine nach dem Feld friends suchen könnte, wenn ein Client dieses Feld abfragt, fügen wir dort eine Funktion hinzu, die aufgerufen wird, wenn ein Client sie benötigt. Diese Funktion fordert mehr Daten von der Datenbank an und gibt ein Array mit weiteren User-Objekten zurück, mit id- und name-Feldern und einer friends-Funktion. Auf diese Weise kann der Client viele Ebenen von Freunden anfordern, die dann von der Engine rekursiv aufgelöst werden.
Als Zusammenfassung: Wenn eine Anfrage das user-Feld enthält, ruft GraphQL die user-Funktion unseres rootValue mit den angegebenen Argumenten auf. Diese Funktion holt ein Benutzerobjekt aus dem Repository, dieses Benutzerobjekt hat 2 einfache Felder (id: number und name: string) und ein Funktionsfeld friends, das alle Freunde des jeweiligen Benutzers aus der Datenbank holt und ein Array von Benutzerobjekten zurückgibt, die für weitere Resolver verwendet werden können.
Was haben wir davon?
Okay, bis jetzt sieht das komplizierter aus als eine typische REST-API. Warum sollten wir uns überhaupt diese Arbeit machen? Die Antwort darauf liegt in der statischen Typisierung, die wir durch GraphQL bekommen. Dadurch, dass Du sowohl im Backend als auch im Frontend Zugriff auf die Typen der API hast, bekommst du viele Vorteile "out of the box":
- Flexibilität / Entkopplung vom Frontend: Da das Backend lediglich die Datentypen mit allen möglichen Feldern anbietet, muss es nicht an die spezifischen Anforderungen verschiedener Oberflächen angepasst werden. Vielleicht benötigt die erste Listenansicht nur eine Zusammenfassung über alle Benutzer, während eine Detailseite andere Felder und Verknüpfungen zu anderen Objekten benötigt. Clients können direkt selbst definieren, welche Felder benötigt sind, ohne jemals Backend-Entwickler einschalten zu müssen.
- Eingebaute Validierung: Da die "Execution Engine" das Schema kennt, kann sie eingehende Anfragen bereits gegen die angegebenen Typen validieren. Sobald eine Anfrage eine Zeichenkette anstelle einer Zahl an das
id-Feld liefert, wirft die Engine einen formatierten Fehler aus, der dem Client mitteilt, was falsch war. Da im Schema auch Pflichtfelder angegeben werden können, brauch man auch nicht auf Nullwerte in der API zu prüfen, wo diese nicht explizit erlaubt sind. - Dokumentation & Erforschung: Es gibt viele Werkzeuge, die das Schema nehmen und interaktive Dokumentations-Tools für die API aufbauen. Eines davon ist GraphiQL:
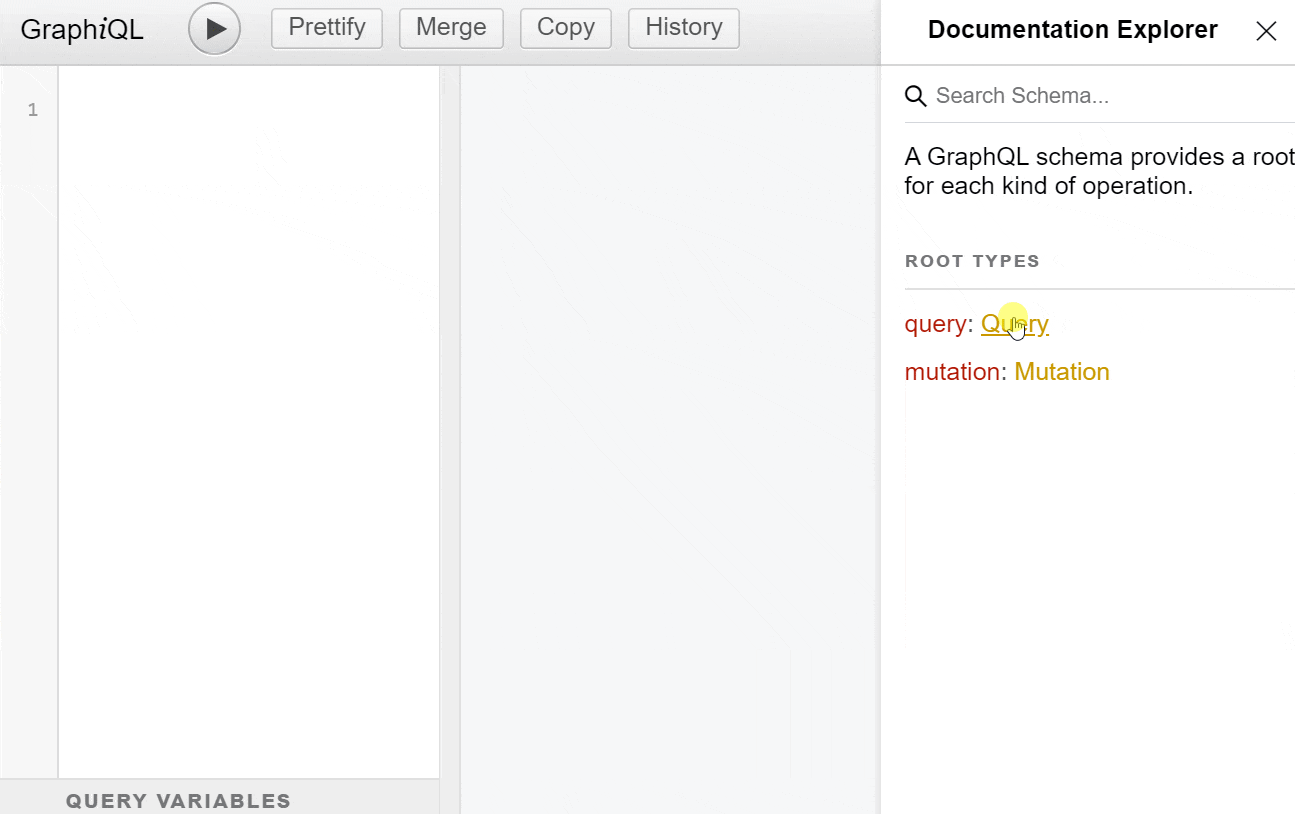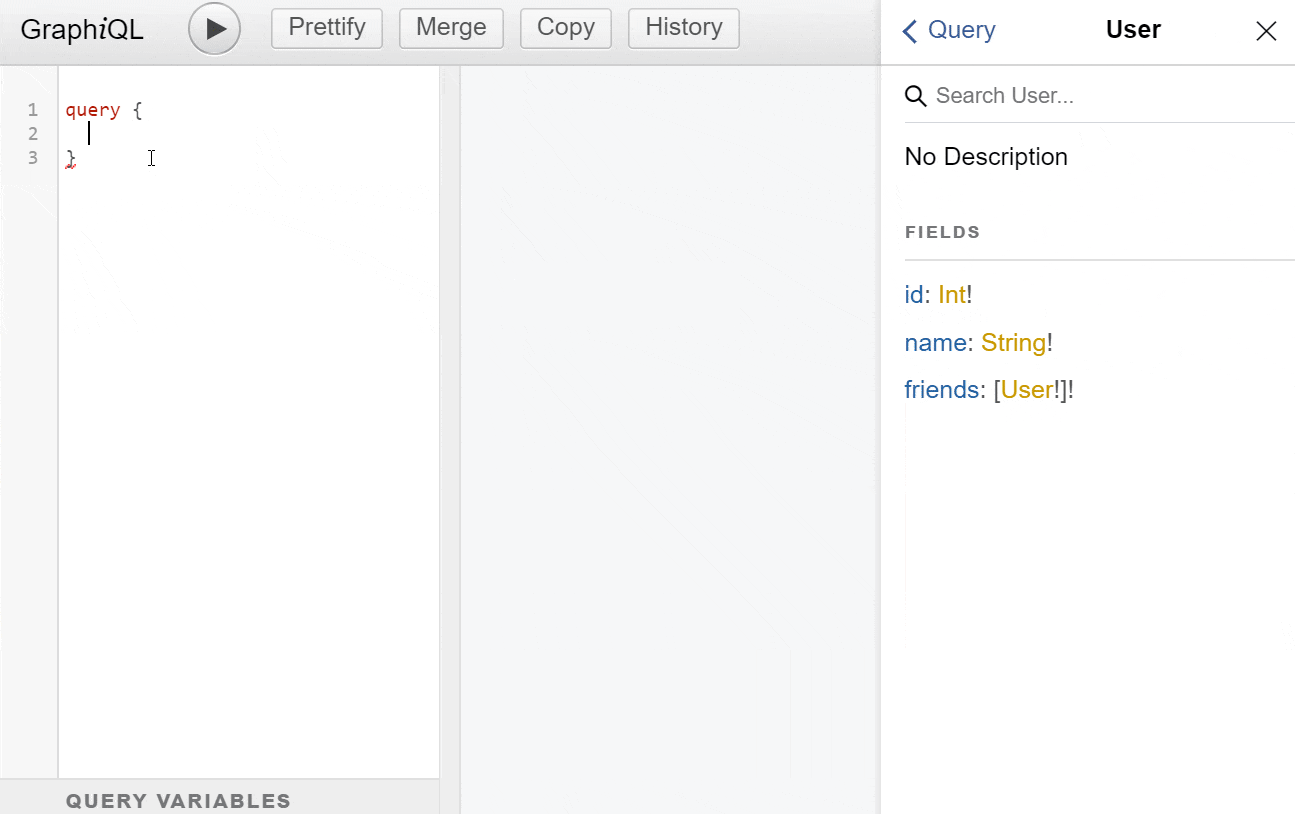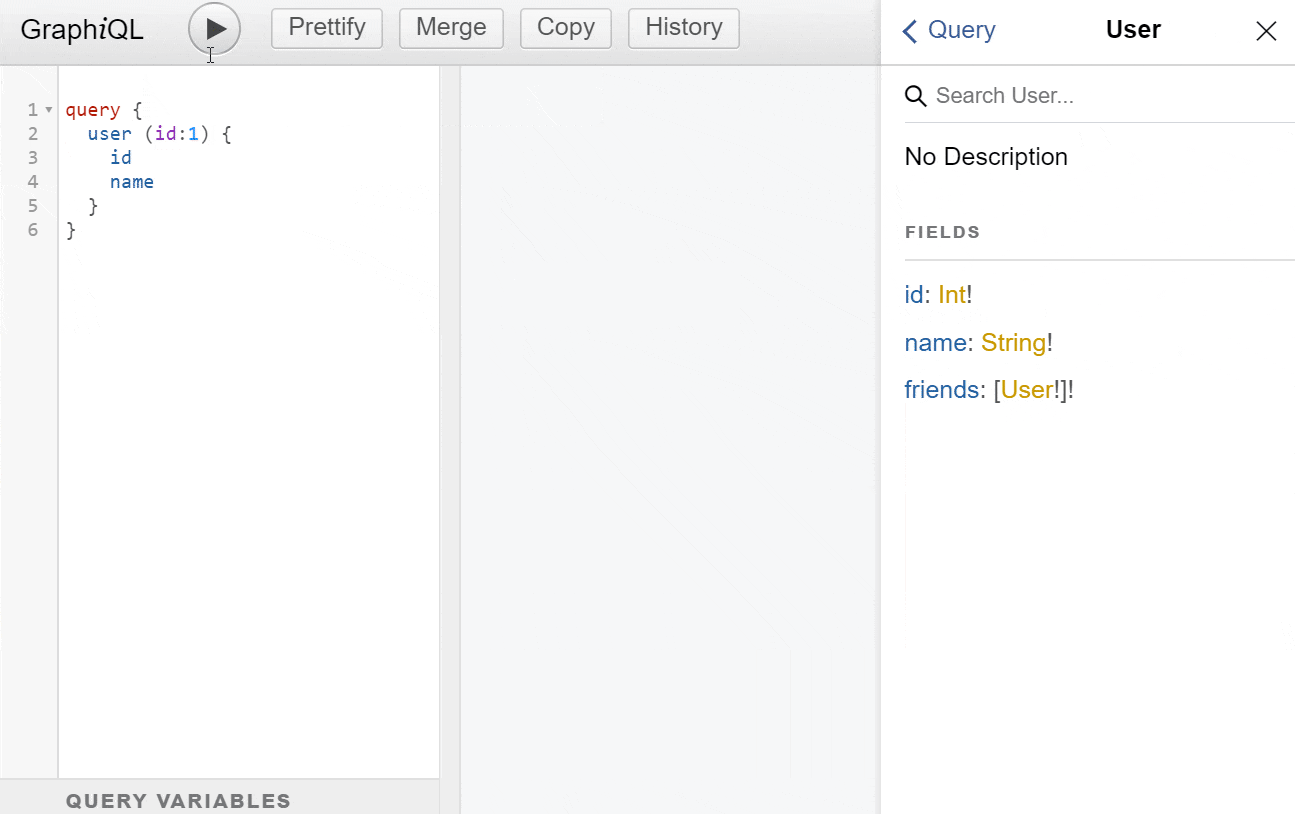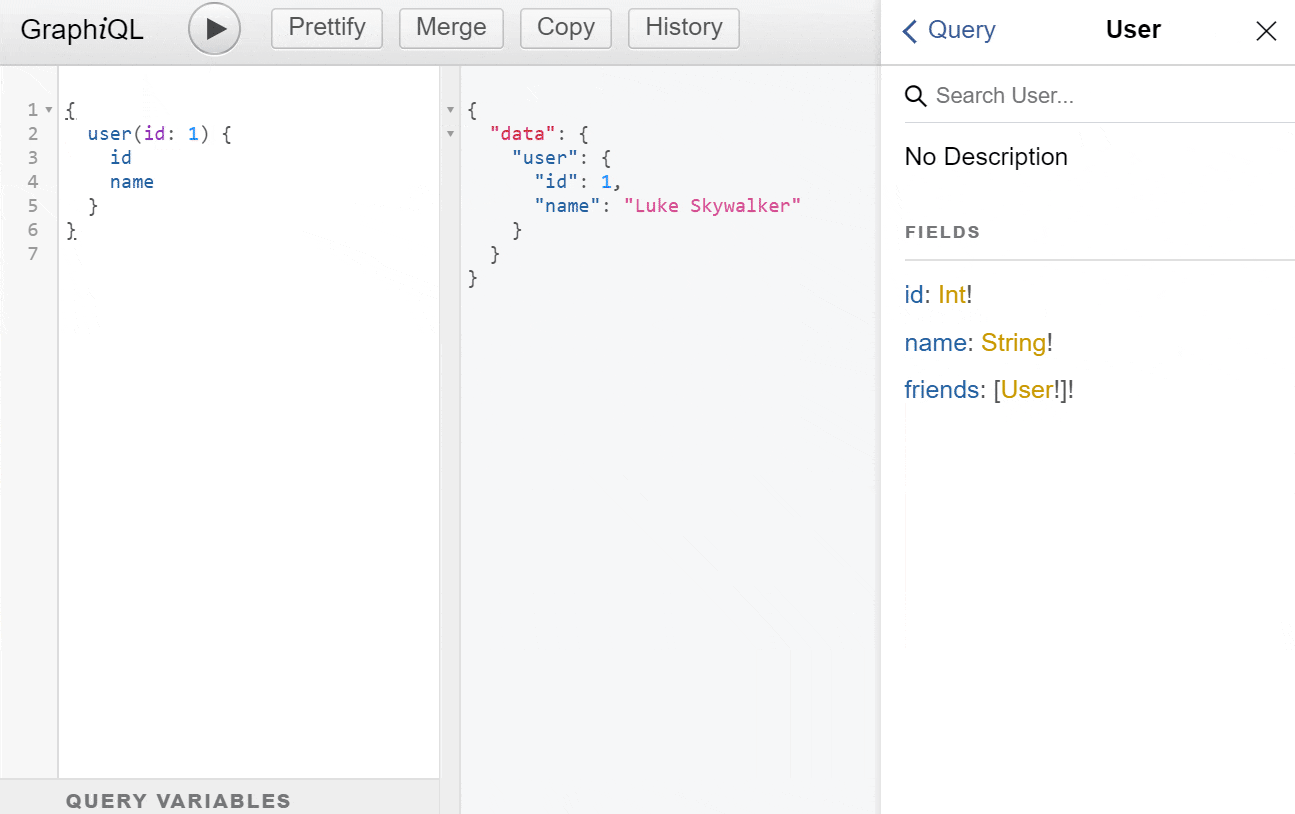
- Datenaggregation: Da für jedes Feld ein eigener
resolverdefiniert werden kann, ist es sehr einfach, den GraphQL-Server als Backend for Frontends zu entwickeln. Das bedeutet, dass ein separates Backend entwickelt wird, das Daten von mehreren anderen (Mikro-) Services aggregiert. Auf diese Weise muss das Frontend nicht über mehrere Services Bescheid wissen, es fragt nur die erforderlichen Felder ab, und der GraphQL-Server delegiert die Anfragen in den Resolver-Funktionen. - Frontend-Werkzeuge: Die Schemadefinition ist nicht nur für die Backend-Seite Deiner Projekte von Nutzen: Du kannst es direkt in Dein Frontend-Repository integrieren und daraus massive Vorteile ziehen: Du kannst eine der clientseitigen GraphQL-Bibliotheken wie Apollo oder Relay verwenden, die das Wissen über das Schema für Caching und Anfrageoptimierung nutzen. Du könntest IDE-Extensions (z.B. für VS-Code) installieren, die das Schema einlesen und Autovervollständigung und Validierung für Abfragen bieten, so dass Du niemals ungültige Abfragen schreibst, oder Du könntest so weit gehen, einen Code-Generator zu verwenden, der alle Deine geschriebenen Abfragen einliest und TypeScript-Typen oder vollständige Abfragefunktionen generiert, sodass Du dich nach dem Einrichten nie wieder um Abfrage-Infrastruktur kümmern musst.
Zusammenfassung: Was ist GraphQL und was ist es nicht?
Wie bereits erklärt, ist GraphQL lediglich die Spezifikation der Sprache und der Execution Engine, die zur Definition und Auflösung von Anfragen verwendet werden. Was die Funktionen im rootValue tun oder welche Netzwerk-Middlewares in Deiner App verwenden werden, ist absolut nicht GraphQL's Angelegenheit. Dinge wie Pagination, Filter, Authentifizierung, Datenbankverbindungen oder Caching sind also NICHT Teil von GraphQL. Es ist Deine Aufgabe als Entwickler, Lösungen für diese Probleme zu finden, oder bewährte Ansätze wie Session-Cookies für die Authentifizierung oder Deine bevorzugte ORM-Bibliothek für die Persistenzschicht zu verwenden. Auf diese Weise kannst Du alle Vorteile von GraphQL nutzen, ohne die Flexibilität in anderen Schichten Deiner Anwendung zu verlieren.
Ausblick: Alles Perfekt mit GraphQL?
Natürlich gibt es einige Herausforderungen bei der Verwendung von GraphQL. Vielleicht hast Du bereits ein Problem mit unserem UserRepository entdeckt. Werfen wir einen Blick auf die folgende Anfrage:
{
user(id: 1) {
id
name
friends {
id
name
friends {
id
name
friends {
id
name
friends {
id
name
friends {
id
name
}
}
}
}
}
}
}
Sieht ein bisschen seltsam aus, ist aber definitiv eine gültige Abfrage, die gestellt werden könnte. Aber das eigentliche Problem ist die Menge der SQL-Abfragen, die durch diese GraphQL-Anfrage erzeugt wird: 117 Abfragen an die Datenbank, um diese eine GraphQL-Abfrage zu beantworten. Und es wird mit jeder Verschachtelungsebene, die wir hinzufügen, exponentiell schlimmer. Dies ist umso überraschender, wenn man bedenkt, dass wir nur 5 verschiedene Benutzer in unserer Datenbank haben. Das ist das gefürchtete N+1 Problem! Auf eine Erklärung der Gründe, die hinter diesem Problem stecken und welche Lösungsansätzen möglich sind, musst Du leider warten, bis der nächste Beitrag in unserem Blog erscheint. Folge mir einfach auf Twitter, damit Du ihn nicht verpasst.







